在数字化浪潮席卷全球的今天,“大数据”已成为一个炙手可热的概念,但对于许多初次接触者而言,它往往显得庞大而抽象,令人感到“懵懂”。简单来说,大数据指的是规模巨大、类型复杂、增长迅速,以至于传统数据处理工具难以在合理时间内进行捕捉、管理和处理的数据集合。它不仅仅是“数据量很大”,更核心的特征通常被概括为“5V”:Volume(体量巨大)、Velocity(生成和处理速度快)、Variety(种类多样)、Value(价值密度低但潜在价值高)、Veracity(真实性或准确性要求高)。
从“懵懂”到理解,关键在于认识到大数据本身并非目的,而是资源。其真正的价值在于通过专业的数据处理和存储支持服务,将海量、杂乱的数据转化为可用的信息和知识,从而驱动决策、优化流程、创新服务。
数据处理支持服务:从原始数据到可用信息
原始的大数据如同未经雕琢的矿石,数据处理服务则是将其提炼成金属的熔炉与工艺。这一过程主要包括:
- 数据采集与集成:从各种来源(如传感器、社交媒体、交易记录、日志文件等)实时或批量地收集数据,并将这些结构、半结构或非结构化的数据整合到一起,形成可供分析的统一视图。
- 数据清洗与预处理:大数据中常包含不完整、不一致、重复或错误的信息。此阶段的任务是“去芜存菁”,通过填补缺失值、纠正错误、标准化格式、去除噪声等操作,提升数据质量,为后续分析奠定可靠基础。
- 数据存储与管理:处理后的数据需要被高效地存放和管理。这引出了与之紧密相连的存储支持服务。
- 数据分析与挖掘:运用统计分析、机器学习、人工智能等技术,从数据中发现模式、趋势、关联和洞见。这是将信息转化为智能的关键步骤,能够支持预测、分类、聚类、推荐等多种应用。
- 数据可视化与呈现:将复杂的分析结果以图表、仪表盘等直观形式展现出来,帮助非技术背景的决策者快速理解数据内涵。
数据存储支持服务:庞大数字资产的基石
没有稳定、可扩展、高效的存储,大数据的处理便无从谈起。存储支持服务构成了整个大数据价值链的物理基础,其核心要求与挑战直接对应大数据的“5V”特性:
- 应对海量体量(Volume):采用分布式存储架构,如Hadoop的HDFS、云对象存储等,能够将数据分散存储在成千上万的普通服务器上,实现近乎无限的横向扩展能力。
- 满足高速处理(Velocity):引入内存数据库、分布式缓存(如Redis)和流数据存储系统,以支持对实时生成数据的快速写入和即时查询分析。
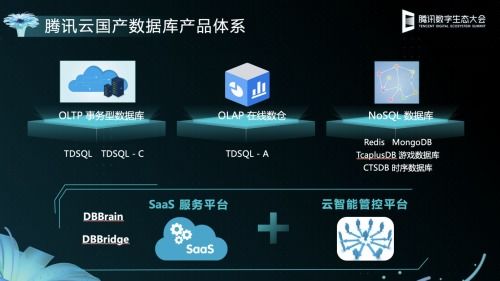
- 容纳多样类型(Variety):提供灵活的数据模型支持,包括关系型数据库(用于结构化数据)、NoSQL数据库(如文档型MongoDB、列族型HBase、图数据库等用于半结构/非结构化数据),以及专门的数据湖(Data Lake)存储,允许以原生格式保存任意类型的数据。
- 保障数据价值与真实性(Value & Veracity):通过冗余备份、容灾机制、访问控制、加密技术等手段,确保数据的持久性、可用性、安全性和一致性,保护高价值的数据资产。
- 成本与效率的平衡:提供分层存储解决方案,根据数据的访问频率和重要性,将其自动存放在性能(如SSD)、成本(如HDD或磁带归档)不同的存储介质上,实现成本优化。
协同驱动的智能引擎
“大数据”概念的落地,离不开数据处理与存储支持服务的深度融合与协同工作。存储系统是数据的“家园”,确保其安全、可靠、可访问;处理服务则是数据的“加工厂”,赋予其意义与智慧。从懵懂到精通,理解这一支撑服务体系,就如同掌握了开启大数据宝藏的钥匙。无论是企业的精准营销、智慧城市的运行管理,还是前沿的科学研究,都建立在这套强大、隐形的数字基础设施之上,持续推动着社会向更加数据驱动的智能化时代迈进。